基于虎书实现LALR(1)分析并生成GLSL编译器前端代码(C#)
为了完美解析GLSL源码,获取其中的信息(都有哪些in/out/uniform等),我决定做个GLSL编译器的前端(以后简称编译器或FrontEndParser)。
以前我做过一个CGCompiler,可以自动生成LL(1)文法的编译器代码(C#语言的)。于是我从《The OpenGL ® Shading Language》(以下简称"PDF")找到一个GLSL的文法,就开始试图将他改写为LL(1)文法。等到我重写了7次后发现,这是不可能的。GLSL的文法超出了LL(1)的范围,必须用更强的分析算法。于是有了现在的LALR(1)Compiler。
理论来源
《现代编译原理-c语言描述》(即"虎书")中提供了详尽的资料。我就以虎书为理论依据。
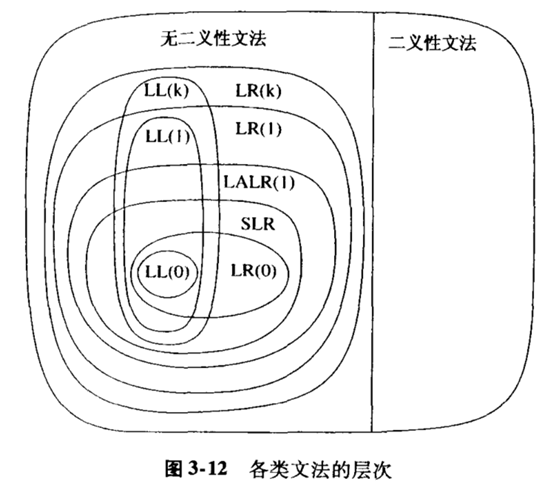
虎书中的下图表明了各种类型的文法的范围。一般正常的程序语言都是符合LALR(1)文法的。
由于LR(0)是SLR的基础,SLR是LR(1)的基础;又由于LR(1)是LALR(1)的基础(这看上去有点奇怪),所以我必须从LR(0)文法开始一步一步实现LALR(1)算法。
输入
给定文法,这个文法所描述的语言的全部信息就都包含进去了。文法里包含了这个语言的关键字、推导结构等所有信息。这也是我觉得YACC那些东西不好的地方:明明有了文法,还得自己整理出各种关键字。
下面是一个文法的例子:
1 // 虎书中的文法3-10 2 <S> ::= <V> "=" <E> ; 3 <S> ::= <E> ; 4 <E> ::= <V> ; 5 <V> ::= "x" ; 6 <V> ::= "*" <E> ;
下面是6个符合此文法的代码:
1 x 2 *x 3 x = x 4 x = * x 5 *x = x 6 **x = **x
输出
输出结果是此文法的编译器代码(C#)。这主要是词法分析器LexicalAnalyzer和语法分析器SyntaxParser两个类。
之后利用C#的CSharpCodeProvider和反射技术来加载、编译、运行生成的代码,用一些例子(例如上面的*x = x)测试是否能正常运行。只要能正常生成语法树,就证明了我的LALR(1)Compiler的实现是正确的。
例如对上述文法的6个示例代码,LALR(1)Compiler可以分别dump出如下的语法树:


1 (__S)[S][<S>] 2 └─(__E)[E][<E>] 3 └─(__V)[V][<V>] 4 └─(__xLeave__)[x][x]
x
1 (__S)[S][<S>] 2 └─(__E)[E][<E>] 3 └─(__V)[V][<V>] 4 ├─(__starLeave__)[*]["*"] 5 └─(__E)[E][<E>] 6 └─(__V)[V][<V>] 7 └─(__xLeave__)[x][x]
*x
1 (__S)[S][<S>] 2 ├─(__V)[V][<V>] 3 │ └─(__xLeave__)[x][x] 4 ├─(__equalLeave__)[=]["="] 5 └─(__E)[E][<E>] 6 └─(__V)[V][<V>] 7 └─(__xLeave__)[x][x]
x = x
1 (__S)[S][<S>] 2 ├─(__V)[V][<V>] 3 │ └─(__xLeave__)[x][x] 4 ├─(__equalLeave__)[=]["="] 5 └─(__E)[E][<E>] 6 └─(__V)[V][<V>] 7 ├─(__starLeave__)[*]["*"] 8 └─(__E)[E][<E>] 9 └─(__V)[V][<V>] 10 └─(__xLeave__)[x][x]
x = * x
1 (__S)[S][<S>] 2 ├─(__V)[V][<V>] 3 │ ├─(__starLeave__)[*]["*"] 4 │ └─(__E)[E][<E>] 5 │ └─(__V)[V][<V>] 6 │ └─(__xLeave__)[x][x] 7 ├─(__equalLeave__)[=]["="] 8 └─(__E)[E][<E>] 9 └─(__V)[V][<V>] 10 └─(__xLeave__)[x][x]
*x = x
1 (__S)[S][<S>] 2 ├─(__V)[V][<V>] 3 │ ├─(__starLeave__)[*]["*"] 4 │ └─(__E)[E][<E>] 5 │ └─(__V)[V][<V>] 6 │ ├─(__starLeave__)[*]["*"] 7 │ └─(__E)[E][<E>] 8 │ └─(__V)[V][<V>] 9 │ └─(__xLeave__)[x][x] 10 ├─(__equalLeave__)[=]["="] 11 └─(__E)[E][<E>] 12 └─(__V)[V][<V>] 13 ├─(__starLeave__)[*]["*"] 14 └─(__E)[E][<E>] 15 └─(__V)[V][<V>] 16 ├─(__starLeave__)[*]["*"] 17 └─(__E)[E][<E>] 18 └─(__V)[V][<V>] 19 └─(__xLeave__)[x][x]
*x = *x
能够正确地导出这些结果,就说明整个库是正确的。其实,只要能导出这些结果而不throw Exception(),就可以断定结果是正确的了
计划
所以我的开发步骤如下:
示例
虎书中已有了文法3-1(如下)的分析表和一个示例分析过程,所以先手工实现文法3-1的分析器。从这个分析器的代码中抽取出所有LR分析器通用的部分,作为LALR(1)Compiler的一部分。
1 // 虎书中的文法3-1
2 <S> ::= <S> ";" <S> ;
3 <S> ::= identifier ":=" <E> ;
4 <S> ::= "print" "(" <L> ")" ;
5 <E> ::= identifier ;
6 <E> ::= number ;
7 <E> ::= <E> "+" <E> ;
8 <E> ::= "(" <S> "," <E> ")" ;
9 <L> ::= <E> ;
10 <L> ::= <L> "," <E> ;
算法
经此之后就对语法分析器的构成心中有数了。下面实现虎书中关于自动生成工具的算法。
最妙的是,即使开始时不理解这些算法的原理,也能够实现之。实现后通过测试用例debug的过程,就很容易理解这些算法了。
LR(0)
首先有两个基础算法。Closure用于补全一个state。Goto用于找到一个state经过某个Node后会进入的下一个state。说是算法,其实却非常简单。虽然简单,要想实现却有很多额外的工作。例如比较两个LR(0)Item的问题。

然后就是计算文法的状态集和边集(Goto动作集)的算法。这个是核心内容。

用此算法可以画出文法3-8的状态图如下:
1 // 虎书中的文法3-8
2 <S> ::= "(" <L> ")" ;
3 <S> ::= "x" ;
4 <L> ::= <S> ;
5 <L> ::= <L> "," <S> ;

最后就是看图作文——构造分析表了。有了分析表,语法分析器的核心部分就完成了。

SLR
在A->α.可以被归约时,只在下一个单词是Follow(A)时才进行归约。看起来很有道理的样子。

LR(1)
LR(1)项(A->α.β,x)指出,序列α在栈顶,且输入中开头的是可以从βx导出的符号。看起来更有道理的样子。

LR(1)的state补全和转换算法也要调整。

然后又是看图作文。

LALR(1)
LALR(1)是对LA(1)的化简处理。他占用空间比LR(1)少,但应用范围也比LR(1)小了点。

为了实现LALR(1),也为了提高LR(1)的效率,必须优化LR(1)State,不能再单纯模仿LR(0)State了。
文法的文法
输入的是文法,输出的是编译器代码,这个过程也可以用一个编译器来实现。这个特别的编译器所对应的文法(即描述文法的文法)如下:(此编译器命名为ContextfreeGrammarCompiler)
1 // 文法是1到多个产生式 2 <Grammar> ::= <ProductionList> <Production> ; 3 // 产生式列表是0到多个产生式 4 <ProductionList> ::= <ProductionList> <Production> | null ; 5 // 产生式是左部+第一个候选式+若干右部 6 <Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ; 7 // 候选式是1到多个结点 8 <Canditate> ::= <VList> <V> ; 9 // 结点列表是0到多个结点 10 <VList> ::= <VList> <V> | null ; 11 // 右部列表是0到多个候选式 12 <RightPartList> ::= "|" <Canditate> <RightPartList> | null ; 13 // 结点是非叶结点或叶结点 14 <V> ::= <Vn> | <Vt> ; 15 // 非叶结点是<>括起来的标识符 16 <Vn> ::= "<" identifier ">" ; 17 // 叶结点是用"引起来的字符串常量或下列内容:null, identifier, number, constString, userDefinedType 18 // 这几个标识符就是ContextfreeGrammar的关键字 19 <Vt> ::= "null" | "identifier" | "number" | "constString" | "userDefinedType"| constString ;
设计
算法看起来还是很简单的。即使不理解他也能实现他。但是实现过程中还是出现了不少的问题。
Hash缓存
如何判定两个对象(LR(0)Item)相同?
这是个不可小觑的问题。
必须重写==、!=运算符,override掉Equals和GetHashCode方法。这样才能判定两个内容相同但不是同一个对象的Item、State相等。
对于LR(0)Item的比较,在计算过程中有太多次,这对于实际应用(例如GLSL的文法)是不可接受的。所以必须缓存这类对象的HashCode。
1 /// <summary>
2 /// 缓存一个对象的hash code。提高比较(==、!=、Equals、GetHashCode、Compare)的效率。
3 /// </summary>
4 public abstract class HashCache : IComparable<HashCache>
5 {
6 public static bool operator ==(HashCache left, HashCache right)
7 {
8 object leftObj = left, rightObj = right;
9 if (leftObj == null)
10 {
11 if (rightObj == null) { return true; }
12 else { return false; }
13 }
14 else
15 {
16 if (rightObj == null) { return false; }
17 }
18
19 return left.Equals(right);
20 }
21
22 public static bool operator !=(HashCache left, HashCache right)
23 {
24 return !(left == right);
25 }
26
27 public override bool Equals(object obj)
28 {
29 HashCache p = obj as HashCache;
30 if ((System.Object)p == null)
31 {
32 return false;
33 }
34
35 return this.HashCode == p.HashCode;
36 }
37
38 public override int GetHashCode()
39 {
40 return this.HashCode;
41 }
42
43 private Func<HashCache, string> GetUniqueString;
44
45 private bool dirty = true;
46
47 /// <summary>
48 /// 指明此cache需要更新才能用。
49 /// </summary>
50 public void SetDirty() { this.dirty = true; }
51
52 private int hashCode;
53 /// <summary>
54 /// hash值。
55 /// </summary>
56 public int HashCode
57 {
58 get
59 {
60 if (this.dirty)
61 {
62 Update();
63
64 this.dirty = false;
65 }
66
67 return this.hashCode;
68 }
69 }
70
71 private void Update()
72 {
73 string str = GetUniqueString(this);
74 int hashCode = str.GetHashCode();
75 this.hashCode = hashCode;
76 #if DEBUG
77 this.uniqueString = str;// debug时可以看到可读的信息
78 #else
79 this.uniqueString = string.Format("[{0}]", hashCode);// release后用最少的内存区分此对象
80 #endif
81 }
82
83 // TODO: 功能稳定后应精简此字段的内容。
84 /// <summary>
85 /// 功能稳定后应精简此字段的内容。
86 /// </summary>
87 private string uniqueString = string.Empty;
88
89 /// <summary>
90 /// 可唯一标识该对象的字符串。
91 /// 功能稳定后应精简此字段的内容。
92 /// </summary>
93 public string UniqueString
94 {
95 get
96 {
97 if (this.dirty)
98 {
99 Update();
100
101 this.dirty = false;
102 }
103
104 return this.uniqueString;
105 }
106 }
107
108 /// <summary>
109 /// 缓存一个对象的hash code。提高比较(==、!=、Equals、GetHashCode、Compare)的效率。
110 /// </summary>
111 /// <param name="GetUniqueString">获取一个可唯一标识此对象的字符串。</param>
112 public HashCache(Func<HashCache, string> GetUniqueString)
113 {
114 if (GetUniqueString == null) { throw new ArgumentNullException(); }
115
116 this.GetUniqueString = GetUniqueString;
117 }
118
119 public override string ToString()
120 {
121 return this.UniqueString;
122 }
123
124 public int CompareTo(HashCache other)
125 {
126 if (other == null) { return 1; }
127
128 if (this.HashCode < other.HashCode)// 如果用this.HashCode - other.HashCode < 0,就会发生溢出,这个bug让我折腾了近8个小时。
129 { return -1; }
130 else if (this.HashCode == other.HashCode)
131 { return 0; }
132 else
133 { return 1; }
134 }
135 }
HashCache
有序集合
如何判定两个集合(LR(0)State)相同?
一个LR(0)State是一个集合,集合内部的元素是没有先后顺序的区别的。但是为了比较两个State,其内部元素必须是有序的(这就可以用二分法进行插入和比较)。否则比较两个State会耗费太多时间。为了尽可能快地比较State,也要缓存State的HashCode。
有序集合的应用广泛,因此独立成类。
1 /// <summary>
2 /// 经过优化的列表。插入新元素用二分法,速度更快,但使用者不能控制元素的位置。
3 /// 对于LALR(1)Compiler项目,只需支持“添加元素”的功能,所以我没有写修改和删除元素的功能。
4 /// </summary>
5 /// <typeparam name="T">元素也要支持快速比较。</typeparam>
6 public class OrderedCollection<T> :
7 HashCache // 快速比较两个OrderedCollection<T>是否相同。
8 , IEnumerable<T> // 可枚举该集合的元素。
9 where T : HashCache // 元素也要支持快速比较。
10 {
11 private List<T> list = new List<T>();
12 private string seperator = Environment.NewLine;
13
14 /// <summary>
15 /// 这是一个只能添加元素的集合,其元素是有序的,是按二分法插入的。
16 /// 但是使用者不能控制元素的顺序。
17 /// </summary>
18 /// <param name="separator">在Dump到流时用什么分隔符分隔各个元素?</param>
19 public OrderedCollection(string separator)
20 : base(GetUniqueString)
21 {
22 this.seperator = separator;
23 }
24
25 private static string GetUniqueString(HashCache cache)
26 {
27 OrderedCollection<T> obj = cache as OrderedCollection<T>;
28 return obj.Dump();
29 }
30
31 public virtual bool TryInsert(T item)
32 {
33 if (this.list.TryBinaryInsert(item))
34 {
35 this.SetDirty();
36 return true;
37 }
38 else
39 {
40 return false;
41 }
42 }
43
44 public int IndexOf(T item)
45 {
46 return this.list.BinarySearch(item);
47 }
48
49 public bool Contains(T item)
50 {
51 int index = this.list.BinarySearch(item);
52 return (0 <= index && index < this.list.Count);
53 }
54
55 public T this[int index] { get { return this.list[index]; } }
56
57 public IEnumerator<T> GetEnumerator()
58 {
59 foreach (var item in this.list)
60 {
61 yield return item;
62 }
63 }
64
65 public int Count { get { return this.list.Count; } }
66
67 System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
68 {
69 return this.GetEnumerator();
70 }
71
72 public override void Dump(System.IO.TextWriter stream)
73 {
74 for (int i = 0; i < this.list.Count; i++)
75 {
76 this.list[i].Dump(stream);
77 if (i + 1 < this.list.Count)
78 {
79 stream.Write(this.seperator);
80 }
81 }
82 }
83 }
OrderedCollection<T>
其中有个TryBinaryInsert的扩展方法,用于向 IList<T> 插入元素。这个方法我经过严格测试。如果有发现此方法的bug向我说明,我愿意奖励¥100元。
1 /// <summary>
2 /// 尝试插入新元素。如果存在相同的元素,就不插入,并返回false。否则返回true。
3 /// </summary>
4 /// <typeparam name="T"></typeparam>
5 /// <param name="list"></param>
6 /// <param name="item"></param>
7 /// <returns></returns>
8 public static bool TryBinaryInsert<T>(this List<T> list, T item)
9 where T : IComparable<T>
10 {
11 bool inserted = false;
12
13 if (list == null || item == null) { return inserted; }
14
15 int left = 0, right = list.Count - 1;
16 if (right < 0)
17 {
18 list.Add(item);
19 inserted = true;
20 }
21 else
22 {
23 while (left < right)
24 {
25 int mid = (left + right) / 2;
26 T current = list[mid];
27 int result = item.CompareTo(current);
28 if (result < 0)
29 { right = mid; }
30 else if (result == 0)
31 { left = mid; right = mid; }
32 else
33 { left = mid + 1; }
34 }
35 {
36 T current = list[left];
37 int result = item.CompareTo(current);
38 if (result < 0)
39 {
40 list.Insert(left, item);
41 inserted = true;
42 }
43 else if (result > 0)
44 {
45 list.Insert(left + 1, item);
46 inserted = true;
47 }
48 }
49 }
50
51 return inserted;
52 }
TryBinaryInsert<T>(this IList<T> list, T item) where T : IComparable<T>
迭代到不动点
虎书中的算法大量使用了迭代到不动点的方式。

这个方法虽好,却仍有可优化的余地。而且这属于核心的计算过程,也应当优化。
优化方法也简单,用一个Queue代替"迭代不动点"的方式即可。这就避免了很多不必要的重复计算。
1 /// <summary>
2 /// LR(0)的Closure操作。
3 /// 补全一个状态。
4 /// </summary>
5 /// <param name="list"></param>
6 /// <param name="state"></param>
7 /// <returns></returns>
8 static LR0State Closure(this RegulationList list, LR0State state)
9 {
10 Queue<LR0Item> queue = new Queue<LR0Item>();
11 foreach (var item in state)
12 {
13 queue.Enqueue(item);
14 }
15 while (queue.Count > 0)
16 {
17 LR0Item item = queue.Dequeue();
18 TreeNodeType node = item.GetNodeNext2Dot();
19 if (node == null) { continue; }
20
21 foreach (var regulation in list)
22 {
23 if (regulation.Left == node)
24 {
25 var newItem = new LR0Item(regulation, 0);
26 if (state.TryInsert(newItem))
27 {
28 queue.Enqueue(newItem);
29 }
30 }
31 }
32 }
33
34 return state;
35 }
Closure
测试
以前我总喜欢做个非常精致的GUI来测试。现在发现没那个必要,简单的Console就可以了。
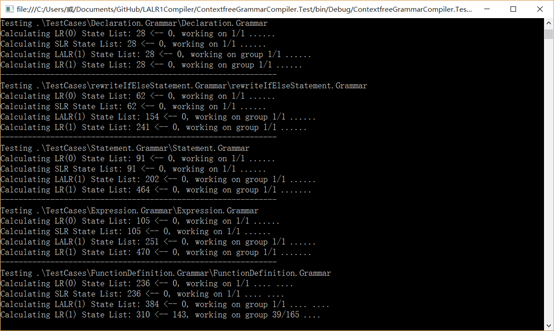
详细的测试结果导出到文件里,可以慢慢查看分析。
1 =====> Processing .\TestCases\3_8.Grammar\3_8.Grammar 2 Get grammar from source code... 3 Dump 3_8.TokenList.log 4 Dump 3_8.Tree.log 5 Dump 3_8.FormatedGrammar.log 6 Dump 3_8.FIRST.log 7 Dump 3_8.FOLLOW.log 8 LR(0) parsing... 9 Dump 3_8.State.log 10 Dump 3_8.Edge.log 11 Dump LR(0) Compiler's source code... 12 SLR parsing... 13 Dump 3_8.State.log 14 Dump 3_8.Edge.log 15 Dump SLR Compiler's source code... 16 LALR(1) parsing... 17 Dump 3_8.State.log 18 Dump 3_8.Edge.log 19 Dump LALR(1) Compiler's source code... 20 LR(1) parsing... 21 Dump 3_8.State.log 22 Dump 3_8.Edge.log 23 Dump LR(1) Compiler's source code... 24 Compiling 3_8 of LR(0) version 25 Test Code 3_8 of LR(0) version 26 Compiling 3_8 of SLR version 27 Test Code 3_8 of SLR version 28 Compiling 3_8 of LALR(1) version 29 Test Code 3_8 of LALR(1) version 30 Compiling 3_8 of LR(1) version 31 Test Code 3_8 of LR(1) version 32 =====> Processing .\TestCases\Demo.Grammar\Demo.Grammar 33 Get grammar from source code... 34 Dump Demo.TokenList.log 35 Dump Demo.Tree.log 36 Dump Demo.FormatedGrammar.log 37 Dump Demo.FIRST.log 38 Dump Demo.FOLLOW.log 39 LR(0) parsing... 40 Dump Demo.State.log 41 Dump Demo.Edge.log 42 Dump LR(0) Compiler's source code... 43 【Exists 5 Conflicts in Parsingmap】 44 SLR parsing... 45 Dump Demo.State.log 46 Dump Demo.Edge.log 47 Dump SLR Compiler's source code... 48 【Exists 2 Conflicts in Parsingmap】 49 LALR(1) parsing... 50 Dump Demo.State.log 51 Dump Demo.Edge.log 52 Dump LALR(1) Compiler's source code... 53 【Exists 2 Conflicts in Parsingmap】 54 LR(1) parsing... 55 Dump Demo.State.log 56 Dump Demo.Edge.log 57 Dump LR(1) Compiler's source code... 58 【Exists 6 Conflicts in Parsingmap】 59 Compiling Demo of LR(0) version 60 Test Code Demo of LR(0) version 61 No need to Test Code with conflicts in SyntaxParser 62 Compiling Demo of SLR version 63 Test Code Demo of SLR version 64 No need to Test Code with conflicts in SyntaxParser 65 Compiling Demo of LALR(1) version 66 Test Code Demo of LALR(1) version 67 No need to Test Code with conflicts in SyntaxParser 68 Compiling Demo of LR(1) version 69 Test Code Demo of LR(1) version 70 No need to Test Code with conflicts in SyntaxParser 71 =====> Processing .\TestCases\GLSL.Grammar\GLSL.Grammar 72 Get grammar from source code... 73 Dump GLSL.TokenList.log 74 Dump GLSL.Tree.log 75 Dump GLSL.FormatedGrammar.log 76 Dump GLSL.FIRST.log 77 Dump GLSL.FOLLOW.log 78 LR(0) parsing...
Test.log
初战GLSL
测试完成后,就可以磨刀霍霍向GLSL文法了。由于GLSL文法比那些测试用的文法规模大的多,最初的版本里,计算过程居然花了好几个小时。最终出现内存不足的Exception,不得不进行优化。
书中给的GLSL文法也是比较奇葩。或许是有什么特别的门道我没有看懂吧。总之要降低难度先。
思路是,把grammar拆分成几个部分,分别处理。
首先是Expression,这是其他部分的基础。Expression部分是符合SLR的,非常好。
然后是statement,statement里有个else悬空的问题,幸好虎书里专门对这个问题做了说明,说可以容忍这个冲突,直接选择Shift,忽略Reduction即可。也非常好。
然后是function_definition,出乎意料的是这部分也是符合SLR的。Nice。
最后是declaration,这里遇到了意想不到的大麻烦。GLSL文法里有个<TYPE_NAME>。这个东西我研究了好久,最后发现他代表的含义竟然是"在读取源代码时动态发现的用户定义的类型"。比如 struct LightInfo{ … } ,他代表的是 LightInfo 这种类型。如果简单的用identifier代替<TYPE_NAME>,文法就会产生无法解决的冲突。
我只好就此打住,先去实现另一种更强的分析方式——同步分析。
同步分析
现在,我的词法分析、语法分析是分开进行的。词法分析全部完成后,才把单词流交给语法分析器进行分析。为了及时识别出用户自定义的类型,这种方式完全不行,必须用"分析一个单词->语法分析->可能的语义分析->分析一个单词"这样的同步分析方式。例如下面的代码:
1 struct LightInfo {
2 vec4 Position; // Light position in eyecoords.
3 vec3 La; // Ambient light intensity
4 vec3 Ld; // Diffuse light intensity
5 vec3 Ls; // Specular light intensity
6 };
7 uniform LightInfo Light;
在读到第二个单词"LightInfo"后,就必须立即将这个"LightInfo"类型加到用户自定义的类型表里。这样,在继续读到"uniform LightInfo Light"里的"LightInfo"时,词法分析器才会知道"LightInfo"是一个userDefinedType,而不是一个随随便便的identifier。(对照上文的文法的文法,可见为实现一个看似不起眼的userDefinedType需要做多少事)
前端分析器(FrontEndParser)
既然要同步解析了,那么词法分析和语法分析就是结结实实绑在一起的过程,所有用个FrontEndParser封装一下就很有必要。其中的UserDefinedTypeCollection就用来记录用户自定义的类型。
1 /// <summary>
2 /// 前端分析器。
3 /// 词法分析、语法分析、语义动作同步进行。
4 /// </summary>
5 public class FrontEndParser
6 {
7 private LexicalAnalyzer lexicalAnalyzer;
8 private LRSyntaxParser syntaxParser;
9
10 public FrontEndParser(LexicalAnalyzer lexicalAnalyzer, LRSyntaxParser syntaxParser)
11 {
12 this.lexicalAnalyzer = lexicalAnalyzer;
13 this.syntaxParser = syntaxParser;
14 }
15
16 /// <summary>
17 /// 词法分析、语法分析、语义动作同步进行。
18 /// </summary>
19 /// <param name="sourceCode"></param>
20 /// <param name="tokenList"></param>
21 /// <returns></returns>
22 public SyntaxTree Parse(string sourceCode, out TokenList tokenList)
23 {
24 tokenList = new TokenList();
25 UserDefinedTypeCollection userDefinedTypeTable = new UserDefinedTypeCollection();
26 this.lexicalAnalyzer.StartAnalyzing(userDefinedTypeTable);
27 this.syntaxParser.StartParsing(userDefinedTypeTable);
28 foreach (var token in this.lexicalAnalyzer.AnalyzeStep(sourceCode))
29 {
30 tokenList.Add(token);
31 this.syntaxParser.ParseStep(token);
32 }
33
34 SyntaxTree result = this.syntaxParser.StopParsing();
35 return result;
36 }
37 }
同步词法分析
词法分析器需要每读取一个单词就返回之,等待语法分析、语义分析结束后再继续。C#的 yield return 语法糖真是甜。
1 public abstract partial class LexicalAnalyzer
2 {
3 protected UserDefinedTypeCollection userDefinedTypeTable;
4 private bool inAnalyzingStep = false;
5
6 internal void StartAnalyzing(UserDefinedTypeCollection userDefinedTypeTable)
7 {
8 if (!inAnalyzingStep)
9 {
10 this.userDefinedTypeTable = userDefinedTypeTable;
11 inAnalyzingStep = true;
12 }
13 }
14
15 internal void StopAnalyzing()
16 {
17 if (inAnalyzingStep)
18 {
19 this.userDefinedTypeTable = null;
20 inAnalyzingStep = false;
21 }
22 }
23
24 /// <summary>
25 /// 每次分析都返回一个<see cref="Token"/>。
26 /// </summary>
27 /// <param name="sourceCode"></param>
28 /// <returns></returns>
29 internal IEnumerable<Token> AnalyzeStep(string sourceCode)
30 {
31 if (!inAnalyzingStep) { throw new Exception("Must invoke this.StartAnalyzing() first!"); }
32
33 if (!string.IsNullOrEmpty(sourceCode))
34 {
35 var context = new AnalyzingContext(sourceCode);
36 int count = sourceCode.Length;
37
38 while (context.NextLetterIndex < count)
39 {
40 Token token = NextToken(context);
41 if (token != null)
42 {
43 yield return token;
44 }
45 }
46 }
47
48 this.StopAnalyzing();
49 }
50 }
同步词法分析
同步语法/语义分析
每次只获取一个新单词,据此执行可能的分析步骤。如果分析动作还绑定了语义分析(这里是为了找到自定义类型),也执行之。
1 public abstract partial class LRSyntaxParser
2 {
3 bool inParsingStep = false;
4 ParsingStepContext parsingStepContext;
5
6 internal void StartParsing(UserDefinedTypeCollection userDefinedTypeTable)
7 {
8 if (!inParsingStep)
9 {
10 LRParsingMap parsingMap = GetParsingMap();
11 RegulationList grammar = GetGrammar();
12 var tokenTypeConvertor = new TokenType2TreeNodeType();
13 parsingStepContext = new ParsingStepContext(
14 grammar, parsingMap, tokenTypeConvertor, userDefinedTypeTable);
15 inParsingStep = true;
16 }
17 }
18
19 internal SyntaxTree StopParsing()
20 {
21 SyntaxTree result = null;
22 if (inParsingStep)
23 {
24 result = ParseStep(Token.endOfTokenList);
25 parsingStepContext.TokenList.RemoveAt(parsingStepContext.TokenList.Count - 1);
26 parsingStepContext = null;
27 inParsingStep = false;
28 }
29
30 return result;
31 }
32 /// <summary>
33 /// 获取归约动作对应的语义动作。
34 /// </summary>
35 /// <param name="parsingAction"></param>
36 /// <returns></returns>
37 protected virtual Action<ParsingStepContext> GetSemanticAction(LRParsingAction parsingAction)
38 {
39 return null;
40 }
41
42 internal SyntaxTree ParseStep(Token token)
43 {
44 if (!inParsingStep) { throw new Exception("Must invoke this.StartParsing() first!"); }
45
46 parsingStepContext.AddToken(token);
47
48 while (parsingStepContext.CurrentTokenIndex < parsingStepContext.TokenList.Count)
49 {
50 // 语法分析
51 TreeNodeType nodeType = parsingStepContext.CurrentNodeType();
52 int stateId = parsingStepContext.StateIdStack.Peek();
53 LRParsingAction action = parsingStepContext.ParsingMap.GetAction(stateId, nodeType);
54 int currentTokenIndex = action.Execute(parsingStepContext);
55 parsingStepContext.CurrentTokenIndex = currentTokenIndex;
56 // 语义分析
57 Action<ParsingStepContext> semanticAction = GetSemanticAction(action);
58 if (semanticAction != null)
59 {
60 semanticAction(parsingStepContext);
61 }
62 }
63
64 if (parsingStepContext.TreeStack.Count > 0)
65 {
66 return parsingStepContext.TreeStack.Peek();
67 }
68 else
69 {
70 return new SyntaxTree();
71 }
72 }
73 }
同步语法/语义分析
再战GLSL
此时武器终于齐备。
文法->解析器
为下面的GLSL文法生成解析器,我的笔记本花费大概10分钟左右。
1 <translation_unit> ::= <external_declaration> ;
2 <translation_unit> ::= <translation_unit> <external_declaration> ;
3 <external_declaration> ::= <function_definition> ;
4 <external_declaration> ::= <declaration> ;
5 <function_definition> ::= <function_prototype> <compound_statement_no_new_scope> ;
6 <variable_identifier> ::= identifier ;
7 <primary_expression> ::= <variable_identifier> ;
8 <primary_expression> ::= number ;
9 <primary_expression> ::= number ;
10 <primary_expression> ::= number ;
11 <primary_expression> ::= <BOOLCONSTANT> ;
12 <primary_expression> ::= number ;
13 <primary_expression> ::= "(" <expression> ")" ;
14 <BOOLCONSTANT> ::= "true" ;
15 <BOOLCONSTANT> ::= "false" ;
16 <postfix_expression> ::= <primary_expression> ;
17 <postfix_expression> ::= <postfix_expression> "[" <integer_expression> "]" ;
18 <postfix_expression> ::= <function_call> ;
19 <postfix_expression> ::= <postfix_expression> "." <FIELD_SELECTION> ;
20 <postfix_expression> ::= <postfix_expression> "++" ;
21 <postfix_expression> ::= <postfix_expression> "--" ;
22 <FIELD_SELECTION> ::= identifier ;
23 <integer_expression> ::= <expression> ;
24 <function_call> ::= <function_call_or_method> ;
25 <function_call_or_method> ::= <function_call_generic> ;
26 <function_call_generic> ::= <function_call_header_with_parameters> ")" ;
27 <function_call_generic> ::= <function_call_header_no_parameters> ")" ;
28 <function_call_header_no_parameters> ::= <function_call_header> "void" ;
29 <function_call_header_no_parameters> ::= <function_call_header> ;
30 <function_call_header_with_parameters> ::= <function_call_header> <assignment_expression> ;
31 <function_call_header_with_parameters> ::= <function_call_header_with_parameters> "," <assignment_expression> ;
32 <function_call_header> ::= <function_identifier> "(" ;
33 <function_identifier> ::= <type_specifier> ;
34 <function_identifier> ::= <postfix_expression> ;
35 <unary_expression> ::= <postfix_expression> ;
36 <unary_expression> ::= "++" <unary_expression> ;
37 <unary_expression> ::= "--" <unary_expression> ;
38 <unary_expression> ::= <unary_operator> <unary_expression> ;
39 <unary_operator> ::= "+" ;
40 <unary_operator> ::= "-" ;
41 <unary_operator> ::= "!" ;
42 <unary_operator> ::= "~" ;
43 <multiplicative_expression> ::= <unary_expression> ;
44 <multiplicative_expression> ::= <multiplicative_expression> "*" <unary_expression> ;
45 <multiplicative_expression> ::= <multiplicative_expression> "/" <unary_expression> ;
46 <multiplicative_expression> ::= <multiplicative_expression> "%" <unary_expression> ;
47 <additive_expression> ::= <multiplicative_expression> ;
48 <additive_expression> ::= <additive_expression> "+" <multiplicative_expression> ;
49 <additive_expression> ::= <additive_expression> "-" <multiplicative_expression> ;
50 <shift_expression> ::= <additive_expression> ;
51 <shift_expression> ::= <shift_expression> "<<" <additive_expression> ;
52 <shift_expression> ::= <shift_expression> ">>" <additive_expression> ;
53 <relational_expression> ::= <shift_expression> ;
54 <relational_expression> ::= <relational_expression> "<" <shift_expression> ;
55 <relational_expression> ::= <relational_expression> ">" <shift_expression> ;
56 <relational_expression> ::= <relational_expression> "<=" <shift_expression> ;
57 <relational_expression> ::= <relational_expression> ">=" <shift_expression> ;
58 <equality_expression> ::= <relational_expression> ;
59 <equality_expression> ::= <equality_expression> "==" <relational_expression> ;
60 <equality_expression> ::= <equality_expression> "!=" <relational_expression> ;
61 <and_expression> ::= <equality_expression> ;
62 <and_expression> ::= <and_expression> "&" <equality_expression> ;
63 <exclusive_or_expression> ::= <and_expression> ;
64 <exclusive_or_expression> ::= <exclusive_or_expression> "^" <and_expression> ;
65 <inclusive_or_expression> ::= <exclusive_or_expression> ;
66 <inclusive_or_expression> ::= <inclusive_or_expression> "|" <exclusive_or_expression> ;
67 <logical_and_expression> ::= <inclusive_or_expression> ;
68 <logical_and_expression> ::= <logical_and_expression> "&&" <inclusive_or_expression> ;
69 <logical_xor_expression> ::= <logical_and_expression> ;
70 <logical_xor_expression> ::= <logical_xor_expression> "^^" <logical_and_expression> ;
71 <logical_or_expression> ::= <logical_xor_expression> ;
72 <logical_or_expression> ::= <logical_or_expression> "||" <logical_xor_expression> ;
73 <conditional_expression> ::= <logical_or_expression> ;
74 <conditional_expression> ::= <logical_or_expression> "?" <expression> ":" <assignment_expression> ;
75 <assignment_expression> ::= <conditional_expression> ;
76 <assignment_expression> ::= <unary_expression> <assignment_operator> <assignment_expression> ;
77 <assignment_operator> ::= "=" ;
78 <assignment_operator> ::= "*=" ;
79 <assignment_operator> ::= "/=" ;
80 <assignment_operator> ::= "%=" ;
81 <assignment_operator> ::= "+=" ;
82 <assignment_operator> ::= "-=" ;
83 <assignment_operator> ::= "<<=" ;
84 <assignment_operator> ::= ">>=" ;
85 <assignment_operator> ::= "&=" ;
86 <assignment_operator> ::= "^=" ;
87 <assignment_operator> ::= "|=" ;
88 <expression> ::= <assignment_expression> ;
89 <expression> ::= <expression> "," <assignment_expression> ;
90 <constant_expression> ::= <conditional_expression> ;
91 <declaration> ::= <function_prototype> ";" ;
92 <declaration> ::= <init_declarator_list> ";" ;
93 <declaration> ::= "precision" <precision_qualifier> <type_specifier> ";" ;
94 <declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" ";" ;
95 <declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" identifier ";" ;
96 <declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" identifier <array_specifier> ";" ;
97 <declaration> ::= <type_qualifier> ";" ;
98 <declaration> ::= <type_qualifier> identifier ";" ;
99 <declaration> ::= <type_qualifier> identifier <identifier_list> ";" ;
100 <identifier_list> ::= "," identifier ;
101 <identifier_list> ::= <identifier_list> "," identifier ;
102 <function_prototype> ::= <function_declarator> ")" ;
103 <function_declarator> ::= <function_header> ;
104 <function_declarator> ::= <function_header_with_parameters> ;
105 <function_header_with_parameters> ::= <function_header> <parameter_declaration> ;
106 <function_header_with_parameters> ::= <function_header_with_parameters> "," <parameter_declaration> ;
107 <function_header> ::= <fully_specified_type> identifier "(" ;
108 <parameter_declarator> ::= <type_specifier> identifier ;
109 <parameter_declarator> ::= <type_specifier> identifier <array_specifier> ;
110 <parameter_declaration> ::= <type_qualifier> <parameter_declarator> ;
111 <parameter_declaration> ::= <parameter_declarator> ;
112 <parameter_declaration> ::= <type_qualifier> <parameter_type_specifier> ;
113 <parameter_declaration> ::= <parameter_type_specifier> ;
114 <parameter_type_specifier> ::= <type_specifier> ;
115 <init_declarator_list> ::= <single_declaration> ;
116 <init_declarator_list> ::= <init_declarator_list> "," identifier ;
117 <init_declarator_list> ::= <init_declarator_list> "," identifier <array_specifier> ;
118 <init_declarator_list> ::= <init_declarator_list> "," identifier <array_specifier> "=" <initializer> ;
119 <init_declarator_list> ::= <init_declarator_list> "," identifier "=" <initializer> ;
120 <single_declaration> ::= <fully_specified_type> ;
121 <single_declaration> ::= <fully_specified_type> identifier ;
122 <single_declaration> ::= <fully_specified_type> identifier <array_specifier> ;
123 <single_declaration> ::= <fully_specified_type> identifier <array_specifier> "=" <initializer> ;
124 <single_declaration> ::= <fully_specified_type> identifier "=" <initializer> ;
125 <fully_specified_type> ::= <type_specifier> ;
126 <fully_specified_type> ::= <type_qualifier> <type_specifier> ;
127 <invariant_qualifier> ::= "invariant" ;
128 <interpolation_qualifier> ::= "smooth" ;
129 <interpolation_qualifier> ::= "flat" ;
130 <interpolation_qualifier> ::= "noperspective" ;
131 <layout_qualifier> ::= "layout" "(" <layout_qualifier_id_list> ")" ;
132 <layout_qualifier_id_list> ::= <layout_qualifier_id> ;
133 <layout_qualifier_id_list> ::= <layout_qualifier_id_list> "," <layout_qualifier_id> ;
134 <layout_qualifier_id> ::= identifier ;
135 <layout_qualifier_id> ::= identifier "=" number ;
136 <precise_qualifier> ::= "precise" ;
137 <type_qualifier> ::= <single_type_qualifier> ;
138 <type_qualifier> ::= <type_qualifier> <single_type_qualifier> ;
139 <single_type_qualifier> ::= <storage_qualifier> ;
140 <single_type_qualifier> ::= <layout_qualifier> ;
141 <single_type_qualifier> ::= <precision_qualifier> ;
142 <single_type_qualifier> ::= <interpolation_qualifier> ;
143 <single_type_qualifier> ::= <invariant_qualifier> ;
144 <single_type_qualifier> ::= <precise_qualifier> ;
145 <storage_qualifier> ::= "const" ;
146 <storage_qualifier> ::= "inout" ;
147 <storage_qualifier> ::= "in" ;
148 <storage_qualifier> ::= "out" ;
149 <storage_qualifier> ::= "centroid" ;
150 <storage_qualifier> ::= "patch" ;
151 <storage_qualifier> ::= "sample" ;
152 <storage_qualifier> ::= "uniform" ;
153 <storage_qualifier> ::= "buffer" ;
154 <storage_qualifier> ::= "shared" ;
155 <storage_qualifier> ::= "coherent" ;
156 <storage_qualifier> ::= "volatile" ;
157 <storage_qualifier> ::= "restrict" ;
158 <storage_qualifier> ::= "readonly" ;
159 <storage_qualifier> ::= "writeonly" ;
160 <storage_qualifier> ::= "subroutine" ;
161 <storage_qualifier> ::= "subroutine" "(" <type_name_list> ")" ;
162 <type_name_list> ::= userDefinedType ;
163 <type_name_list> ::= <type_name_list> "," userDefinedType ;
164 <type_specifier> ::= <type_specifier_nonarray> ;
165 <type_specifier> ::= <type_specifier_nonarray> <array_specifier> ;
166 <array_specifier> ::= "[" "]" ;
167 <array_specifier> ::= "[" <constant_expression> "]" ;
168 <array_specifier> ::= <array_specifier> "[" "]" ;
169 <array_specifier> ::= <array_specifier> "[" <constant_expression> "]" ;
170 <type_specifier_nonarray> ::= "void" ;
171 <type_specifier_nonarray> ::= "float" ;
172 <type_specifier_nonarray> ::= "double" ;
173 <type_specifier_nonarray> ::= "int" ;
174 <type_specifier_nonarray> ::= "uint" ;
175 <type_specifier_nonarray> ::= "bool" ;
176 <type_specifier_nonarray> ::= "vec2" ;
177 <type_specifier_nonarray> ::= "vec3" ;
178 <type_specifier_nonarray> ::= "vec4" ;
179 <type_specifier_nonarray> ::= "dvec2" ;
180 <type_specifier_nonarray> ::= "dvec3" ;
181 <type_specifier_nonarray> ::= "dvec4" ;
182 <type_specifier_nonarray> ::= "bvec2" ;
183 <type_specifier_nonarray> ::= "bvec3" ;
184 <type_specifier_nonarray> ::= "bvec4" ;
185 <type_specifier_nonarray> ::= "ivec2" ;
186 <type_specifier_nonarray> ::= "ivec3" ;
187 <type_specifier_nonarray> ::= "ivec4" ;
188 <type_specifier_nonarray> ::= "uvec2" ;
189 <type_specifier_nonarray> ::= "uvec3" ;
190 <type_specifier_nonarray> ::= "uvec4" ;
191 <type_specifier_nonarray> ::= "mat2" ;
192 <type_specifier_nonarray> ::= "mat3" ;
193 <type_specifier_nonarray> ::= "mat4" ;
194 <type_specifier_nonarray> ::= "mat2x2" ;
195 <type_specifier_nonarray> ::= "mat2x3" ;
196 <type_specifier_nonarray> ::= "mat2x4" ;
197 <type_specifier_nonarray> ::= "mat3x2" ;
198 <type_specifier_nonarray> ::= "mat3x3" ;
199 <type_specifier_nonarray> ::= "mat3x4" ;
200 <type_specifier_nonarray> ::= "mat4x2" ;
201 <type_specifier_nonarray> ::= "mat4x3" ;
202 <type_specifier_nonarray> ::= "mat4x4" ;
203 <type_specifier_nonarray> ::= "dmat2" ;
204 <type_specifier_nonarray> ::= "dmat3" ;
205 <type_specifier_nonarray> ::= "dmat4" ;
206 <type_specifier_nonarray> ::= "dmat2x2" ;
207 <type_specifier_nonarray> ::= "dmat2x3" ;
208 <type_specifier_nonarray> ::= "dmat2x4" ;
209 <type_specifier_nonarray> ::= "dmat3x2" ;
210 <type_specifier_nonarray> ::= "dmat3x3" ;
211 <type_specifier_nonarray> ::= "dmat3x4" ;
212 <type_specifier_nonarray> ::= "dmat4x2" ;
213 <type_specifier_nonarray> ::= "dmat4x3" ;
214 <type_specifier_nonarray> ::= "dmat4x4" ;
215 <type_specifier_nonarray> ::= "atomic_uint" ;
216 <type_specifier_nonarray> ::= "sampler1D" ;
217 <type_specifier_nonarray> ::= "sampler2D" ;
218 <type_specifier_nonarray> ::= "sampler3D" ;
219 <type_specifier_nonarray> ::= "samplerCube" ;
220 <type_specifier_nonarray> ::= "sampler1DShadow" ;
221 <type_specifier_nonarray> ::= "sampler2DShadow" ;
222 <type_specifier_nonarray> ::= "samplerCubeShadow" ;
223 <type_specifier_nonarray> ::= "sampler1DArray" ;
224 <type_specifier_nonarray> ::= "sampler2DArray" ;
225 <type_specifier_nonarray> ::= "sampler1DArrayShadow" ;
226 <type_specifier_nonarray> ::= "sampler2DArrayShadow" ;
227 <type_specifier_nonarray> ::= "samplerCubeArray" ;
228 <type_specifier_nonarray> ::= "samplerCubeArrayShadow" ;
229 <type_specifier_nonarray> ::= "isampler1D" ;
230 <type_specifier_nonarray> ::= "isampler2D" ;
231 <type_specifier_nonarray> ::= "isampler3D" ;
232 <type_specifier_nonarray> ::= "isamplerCube" ;
233 <type_specifier_nonarray> ::= "isampler1DArray" ;
234 <type_specifier_nonarray> ::= "isampler2DArray" ;
235 <type_specifier_nonarray> ::= "isamplerCubeArray" ;
236 <type_specifier_nonarray> ::= "usampler1D" ;
237 <type_specifier_nonarray> ::= "usampler2D" ;
238 <type_specifier_nonarray> ::= "usampler3D" ;
239 <type_specifier_nonarray> ::= "usamplerCube" ;
240 <type_specifier_nonarray> ::= "usampler1DArray" ;
241 <type_specifier_nonarray> ::= "usampler2DArray" ;
242 <type_specifier_nonarray> ::= "usamplerCubeArray" ;
243 <type_specifier_nonarray> ::= "sampler2DRect" ;
244 <type_specifier_nonarray> ::= "sampler2DRectShadow" ;
245 <type_specifier_nonarray> ::= "isampler2DRect" ;
246 <type_specifier_nonarray> ::= "usampler2DRect" ;
247 <type_specifier_nonarray> ::= "samplerBuffer" ;
248 <type_specifier_nonarray> ::= "isamplerBuffer" ;
249 <type_specifier_nonarray> ::= "usamplerBuffer" ;
250 <type_specifier_nonarray> ::= "sampler2DMS" ;
251 <type_specifier_nonarray> ::= "isampler2DMS" ;
252 <type_specifier_nonarray> ::= "usampler2DMS" ;
253 <type_specifier_nonarray> ::= "sampler2DMSArray" ;
254 <type_specifier_nonarray> ::= "isampler2DMSArray" ;
255 <type_specifier_nonarray> ::= "usampler2DMSArray" ;
256 <type_specifier_nonarray> ::= "image1D" ;
257 <type_specifier_nonarray> ::= "iimage1D" ;
258 <type_specifier_nonarray> ::= "uimage1D" ;
259 <type_specifier_nonarray> ::= "image2D" ;
260 <type_specifier_nonarray> ::= "iimage2D" ;
261 <type_specifier_nonarray> ::= "uimage2D" ;
262 <type_specifier_nonarray> ::= "image3D" ;
263 <type_specifier_nonarray> ::= "iimage3D" ;
264 <type_specifier_nonarray> ::= "uimage3D" ;
265 <type_specifier_nonarray> ::= "image2DRect" ;
266 <type_specifier_nonarray> ::= "iimage2DRect" ;
267 <type_specifier_nonarray> ::= "uimage2DRect" ;
268 <type_specifier_nonarray> ::= "imageCube" ;
269 <type_specifier_nonarray> ::= "iimageCube" ;
270 <type_specifier_nonarray> ::= "uimageCube" ;
271 <type_specifier_nonarray> ::= "imageBuffer" ;
272 <type_specifier_nonarray> ::= "iimageBuffer" ;
273 <type_specifier_nonarray> ::= "uimageBuffer" ;
274 <type_specifier_nonarray> ::= "image1DArray" ;
275 <type_specifier_nonarray> ::= "iimage1DArray" ;
276 <type_specifier_nonarray> ::= "uimage1DArray" ;
277 <type_specifier_nonarray> ::= "image2DArray" ;
278 <type_specifier_nonarray> ::= "iimage2DArray" ;
279 <type_specifier_nonarray> ::= "uimage2DArray" ;
280 <type_specifier_nonarray> ::= "imageCubeArray" ;
281 <type_specifier_nonarray> ::= "iimageCubeArray" ;
282 <type_specifier_nonarray> ::= "uimageCubeArray" ;
283 <type_specifier_nonarray> ::= "image2DMS" ;
284 <type_specifier_nonarray> ::= "iimage2DMS" ;
285 <type_specifier_nonarray> ::= "uimage2DMS" ;
286 <type_specifier_nonarray> ::= "image2DMSArray" ;
287 <type_specifier_nonarray> ::= "iimage2DMSArray" ;
288 <type_specifier_nonarray> ::= "uimage2DMSArray" ;
289 <type_specifier_nonarray> ::= <struct_specifier> ;
290 <type_specifier_nonarray> ::= userDefinedType ;
291 <precision_qualifier> ::= "high_precision" ;
292 <precision_qualifier> ::= "medium_precision" ;
293 <precision_qualifier> ::= "low_precision" ;
294 // semantic parsing needed
295 <struct_specifier> ::= "struct" identifier "{" <struct_declaration_list> "}" ;
296 <struct_specifier> ::= "struct" "{" <struct_declaration_list> "}" ;
297 <struct_declaration_list> ::= <struct_declaration> ;
298 <struct_declaration_list> ::= <struct_declaration_list> <struct_declaration> ;
299 <struct_declaration> ::= <type_specifier> <struct_declarator_list> ";" ;
300 <struct_declaration> ::= <type_qualifier> <type_specifier> <struct_declarator_list> ";" ;
301 <struct_declarator_list> ::= <struct_declarator> ;
302 <struct_declarator_list> ::= <struct_declarator_list> "," <struct_declarator> ;
303 <struct_declarator> ::= identifier ;
304 <struct_declarator> ::= identifier <array_specifier> ;
305 <initializer> ::= <assignment_expression> ;
306 <initializer> ::= "{" <initializer_list> "}" ;
307 <initializer> ::= "{" <initializer_list> "," "}" ;
308 <initializer_list> ::= <initializer> ;
309 <initializer_list> ::= <initializer_list> "," <initializer> ;
310 <declaration_statement> ::= <declaration> ;
311 <statement> ::= <compound_statement> ;
312 <statement> ::= <simple_statement> ;
313 <simple_statement> ::= <declaration_statement> ;
314 <simple_statement> ::= <expression_statement> ;
315 <simple_statement> ::= <selection_statement> ;
316 <simple_statement> ::= <switch_statement> ;
317 <simple_statement> ::= <case_label> ;
318 <simple_statement> ::= <iteration_statement> ;
319 <simple_statement> ::= <jump_statement> ;
320 <compound_statement> ::= "{" "}" ;
321 <compound_statement> ::= "{" <statement_list> "}" ;
322 <statement_no_new_scope> ::= <compound_statement_no_new_scope> ;
323 <statement_no_new_scope> ::= <simple_statement> ;
324 <compound_statement_no_new_scope> ::= "{" "}" ;
325 <compound_statement_no_new_scope> ::= "{" <statement_list> "}" ;
326 <statement_list> ::= <statement> ;
327 <statement_list> ::= <statement_list> <statement> ;
328 <expression_statement> ::= ";" ;
329 <expression_statement> ::= <expression> ";" ;
330 <selection_statement> ::= "if" "(" <expression> ")" <selection_rest_statement> ;
331 <selection_rest_statement> ::= <statement> "else" <statement> ;
332 <selection_rest_statement> ::= <statement> ;
333 <condition> ::= <expression> ;
334 <condition> ::= <fully_specified_type> identifier "=" <initializer> ;
335 <switch_statement> ::= "switch" "(" <expression> ")" "{" <switch_statement_list> "}" ;
336 <switch_statement_list> ::= <statement_list> ;
337 <case_label> ::= "case" <expression> ":" ;
338 <case_label> ::= "default" ":" ;
339 <iteration_statement> ::= "while" "(" <condition> ")" <statement_no_new_scope> ;
340 <iteration_statement> ::= "do" <statement> "while" "(" <expression> ")" ";" ;
341 <iteration_statement> ::= "for" "(" <for_init_statement> <for_rest_statement> ")" <statement_no_new_scope> ;
342 <for_init_statement> ::= <expression_statement> ;
343 <for_init_statement> ::= <declaration_statement> ;
344 <conditionopt> ::= <condition> ;
345 <for_rest_statement> ::= <conditionopt> ";" ;
346 <for_rest_statement> ::= <conditionopt> ";" <expression> ;
347 <jump_statement> ::= "continue" ";" ;
348 <jump_statement> ::= "break" ";" ;
349 <jump_statement> ::= "return" ";" ;
350 <jump_statement> ::= "return" <expression> ";" ;
351 <jump_statement> ::= "discard" ";" ;
GLSL.Grammar
补充语义分析片段
语义分析是不能自动生成的。此时需要的语义分析,只有找到自定义类型这一个目的。
在GLSL文法里,是下面这个state需要进行语义分析。此时,分析器刚刚读到用户自定义的类型名字(identifier)。
1 State [172]:
2 <struct_specifier> ::= "struct" identifier . "{" <struct_declaration_list> "}" ;, identifier "," ")" "(" ";" "["
语义分析动作内容则十分简单,将identifier的内容作为自定义类型名加入UserDefinedTypeTable即可。
1 // State [172]:
2 // <struct_specifier> ::= "struct" identifier . "{" <struct_declaration_list> "}" ;, identifier "," ")" "(" ";" "["
3 static void state172_struct_specifier(ParsingStepContext context)
4 {
5 SyntaxTree tree = context.TreeStack.Peek();
6 string name = tree.NodeType.Content;
7 context.UserDefinedTypeTable.TryInsert(new UserDefinedType(name));
8 }
当然,别忘了在初始化时将此动作绑定到对应的state上。
1 static GLSLSyntaxParser()
2 {
3 // 将语义动作绑定的到state上。
4 dict.Add(new LR1ShiftInAction(172), state172_struct_specifier);
5 }
6 static Dictionary<LRParsingAction, Action<ParsingStepContext>> dict =
7 new Dictionary<LRParsingAction, Action<ParsingStepContext>>();
8
9 protected override Action<ParsingStepContext> GetSemanticAction(LRParsingAction parsingAction)
10 {
11 Action<ParsingStepContext> semanticAction = null;
12 if (dict.TryGetValue(parsingAction, out semanticAction))
13 {
14 return semanticAction;
15 }
16 else
17 {
18 return null;
19 }
20 }
userDefinedType
下面是上文的LightInfo代码片段的词法分析结果。请注意在定义LightInfo时,他是个identifier,定义之后,就是一个userDefinedType类型的单词了。
1 TokenList[Count: 21]
2 [[struct](__struct)[struct]]$[Ln:1, Col:1]
3 [[LightInfo](identifier)[LightInfo]]$[Ln:1, Col:8]
4 [[{](__left_brace)["{"]]$[Ln:1, Col:18]
5 [[vec4](__vec4)[vec4]]$[Ln:2, Col:5]
6 [[Position](identifier)[Position]]$[Ln:2, Col:10]
7 [[;](__semicolon)[";"]]$[Ln:2, Col:18]
8 [[vec3](__vec3)[vec3]]$[Ln:3, Col:5]
9 [[La](identifier)[La]]$[Ln:3, Col:10]
10 [[;](__semicolon)[";"]]$[Ln:3, Col:12]
11 [[vec3](__vec3)[vec3]]$[Ln:4, Col:5]
12 [[Ld](identifier)[Ld]]$[Ln:4, Col:10]
13 [[;](__semicolon)[";"]]$[Ln:4, Col:12]
14 [[vec3](__vec3)[vec3]]$[Ln:5, Col:5]
15 [[Ls](identifier)[Ls]]$[Ln:5, Col:10]
16 [[;](__semicolon)[";"]]$[Ln:5, Col:12]
17 [[}](__right_brace)["}"]]$[Ln:6, Col:1]
18 [[;](__semicolon)[";"]]$[Ln:6, Col:2]
19 [[uniform](__uniform)[uniform]]$[Ln:7, Col:1]
20 [[LightInfo](__userDefinedType)[LightInfo]]$[Ln:7, Col:9]
21 [[Light](identifier)[Light]]$[Ln:7, Col:19]
22 [[;](__semicolon)[";"]]$[Ln:7, Col:24]
下面是LightInfo片段的语法树。你可以看到单词的类型对照着叶结点的类型。
1 (__translation_unit)[<translation_unit>][translation_unit]
2 ├─(__translation_unit)[<translation_unit>][translation_unit]
3 │ └─(__external_declaration)[<external_declaration>][external_declaration]
4 │ └─(__declaration)[<declaration>][declaration]
5 │ ├─(__init_declarator_list)[<init_declarator_list>][init_declarator_list]
6 │ │ └─(__single_declaration)[<single_declaration>][single_declaration]
7 │ │ └─(__fully_specified_type)[<fully_specified_type>][fully_specified_type]
8 │ │ └─(__type_specifier)[<type_specifier>][type_specifier]
9 │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
10 │ │ └─(__struct_specifier)[<struct_specifier>][struct_specifier]
11 │ │ ├─(__structLeave__)[struct][struct]
12 │ │ ├─(identifierLeave__)[LightInfo][LightInfo]
13 │ │ ├─(__left_braceLeave__)["{"][{]
14 │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
15 │ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
16 │ │ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
17 │ │ │ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
18 │ │ │ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
19 │ │ │ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
20 │ │ │ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
21 │ │ │ │ │ │ │ └─(__vec4Leave__)[vec4][vec4]
22 │ │ │ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
23 │ │ │ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
24 │ │ │ │ │ │ │ └─(identifierLeave__)[Position][Position]
25 │ │ │ │ │ │ └─(__semicolonLeave__)[";"][;]
26 │ │ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
27 │ │ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
28 │ │ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
29 │ │ │ │ │ │ └─(__vec3Leave__)[vec3][vec3]
30 │ │ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
31 │ │ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
32 │ │ │ │ │ │ └─(identifierLeave__)[La][La]
33 │ │ │ │ │ └─(__semicolonLeave__)[";"][;]
34 │ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
35 │ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
36 │ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
37 │ │ │ │ │ └─(__vec3Leave__)[vec3][vec3]
38 │ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
39 │ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
40 │ │ │ │ │ └─(identifierLeave__)[Ld][Ld]
41 │ │ │ │ └─(__semicolonLeave__)[";"][;]
42 │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
43 │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
44 │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
45 │ │ │ │ └─(__vec3Leave__)[vec3][vec3]
46 │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
47 │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
48 │ │ │ │ └─(identifierLeave__)[Ls][Ls]
49 │ │ │ └─(__semicolonLeave__)[";"][;]
50 │ │ └─(__right_braceLeave__)["}"][}]
51 │ └─(__semicolonLeave__)[";"][;]
52 └─(__external_declaration)[<external_declaration>][external_declaration]
53 └─(__declaration)[<declaration>][declaration]
54 ├─(__init_declarator_list)[<init_declarator_list>][init_declarator_list]
55 │ └─(__single_declaration)[<single_declaration>][single_declaration]
56 │ ├─(__fully_specified_type)[<fully_specified_type>][fully_specified_type]
57 │ │ ├─(__type_qualifier)[<type_qualifier>][type_qualifier]
58 │ │ │ └─(__single_type_qualifier)[<single_type_qualifier>][single_type_qualifier]
59 │ │ │ └─(__storage_qualifier)[<storage_qualifier>][storage_qualifier]
60 │ │ │ └─(__uniformLeave__)[uniform][uniform]
61 │ │ └─(__type_specifier)[<type_specifier>][type_specifier]
62 │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
63 │ │ └─(__userDefinedTypeLeave__)[LightInfo][LightInfo]
64 │ └─(identifierLeave__)[Light][Light]
65 └─(__semicolonLeave__)[";"][;]
SyntaxTree
再加上其他的测试用例,这个GLSL解析器终于实现了。
最终目的
解析GLSL源代码,是为了获取其中的信息(都有哪些in/out/uniform等)。现在语法树已经有了,剩下的就是遍历此树的事了。不再详述。
故事
故事,其实是事故。由于心急,此项目第一次实现时出现了几乎无法fix的bug。于是重写了一遍,这次一步一步走,终于成功了。
LALR(1)State
LALR(1)State集合在尝试插入一个新的State时,如果已有在LALR(1)意义上"相等"的状态,仍旧要尝试将新state的LookAhead列表插入已有状态。
否则,下面的例子就显示了文法3-8在忽视了这一点时的state集合与正确的state集合的差别(少了一些LookAhead项)。
1 State [1]:
2 <S> ::= . "(" <L> ")" ;, "$"
3 <S'> ::= . <S> "$" ;, "$"
4 <S> ::= . "x" ;, "$"
5 State [8]:
6 <S> ::= "(" <L> ")" . ;, "$"
7 State [4]:
8 <S> ::= "x" . ;, "$"
9 State [6]:
10 <L> ::= <S> . ;, ","")"
11 State [9]:
12 <L> ::= <L> "," <S> . ;, ","")"
13 State [5]:
14 <L> ::= <L> . "," <S> ;, ","")"
15 <S> ::= "(" <L> . ")" ;, "$"
16 State [7]:
17 <S> ::= . "(" <L> ")" ;, ","")"
18 <S> ::= . "x" ;, ","")"
19 <L> ::= <L> "," . <S> ;, ","")"
20 State [2]:
21 <S> ::= . "(" <L> ")" ;, ","")"
22 <S> ::= . "x" ;, ","")"
23 <S> ::= "(" . <L> ")" ;, "$"
24 <L> ::= . <L> "," <S> ;, ","")"
25 <L> ::= . <S> ;, ","")"
26 State [3]:
27 <S'> ::= <S> . "$" ;, "$"
少LookAhead项的
1 State [1]:
2 <S> ::= . "(" <L> ")" ;, "$"
3 <S'> ::= . <S> "$" ;, "$"
4 <S> ::= . "x" ;, "$"
5 State [8]:
6 <S> ::= "(" <L> ")" . ;, "$"","")"
7 State [4]:
8 <S> ::= "x" . ;, "$"","")"
9 State [6]:
10 <L> ::= <S> . ;, ","")"
11 State [9]:
12 <L> ::= <L> "," <S> . ;, ","")"
13 State [5]:
14 <L> ::= <L> . "," <S> ;, ","")"
15 <S> ::= "(" <L> . ")" ;, "$"","")"
16 State [7]:
17 <S> ::= . "(" <L> ")" ;, ","")"
18 <S> ::= . "x" ;, ","")"
19 <L> ::= <L> "," . <S> ;, ","")"
20 State [2]:
21 <S> ::= . "(" <L> ")" ;, ","")"
22 <S> ::= . "x" ;, ","")"
23 <S> ::= "(" . <L> ")" ;, "$"","")"
24 <L> ::= . <L> "," <S> ;, ","")"
25 <L> ::= . <S> ;, ","")"
26 State [3]:
27 <S'> ::= <S> . "$" ;, "$"
正确的
CodeDom
CodeDom不支持readonly属性,实在是遗憾。CodeDom还会对以"__"开头的变量自动添加个@前缀,真是无语。
1 // private static TreeNodeType NODE__Grammar = new TreeNodeType(ContextfreeGrammarSLRTreeNodeType.NODE__Grammar, "Grammar", "<Grammar>"); 2 CodeMemberField field = new CodeMemberField(typeof(TreeNodeType), GetNodeNameInParser(node)); 3 // field.Attributes 不支持readonly,遗憾了。 4 field.Attributes = MemberAttributes.Private | MemberAttributes.Static; 5 var ctor = new CodeObjectCreateExpression(typeof(TreeNodeType), 6 new CodeFieldReferenceExpression( 7 new CodeTypeReferenceExpression(GetTreeNodeConstTypeName(grammarId, algorithm)), 8 GetNodeNameInParser(node)), 9 new CodePrimitiveExpression(node.Content), 10 new CodePrimitiveExpression(node.Nickname)); 11 field.InitExpression = ctor;
复杂的词法分析器
从算法上说,理解语法分析器要比较理解词法分析器困难的多。但是LR语法分析器的结构却比词法分析器的结构和LL语法分析器的结果简单得多。目前实现dump词法分析器代码的代码是最绕的。要处理注释(//和/**/)是其中最复杂的问题。这段代码写好了我再也不想动了。
LL和LR
LR分析法确实比LL强太多。其适用各种现今的程序语言,对文法的限制极少,分析器结构还十分简单。奇妙的是,稍微改动下文法,就可以减少LR分析的state,精简代码。
例如ContextfreeGrammarCompiler的文法,稍微改改会有不同的state数目。
1 ==================================================================== 2 135 set action items 3 <Grammar> ::= <ProductionList> <Production> ; 4 <ProductionList> ::= <ProductionList> <Production> | null ; 5 <Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ; 6 <Canditate> ::= <V> <VList> ; 7 <VList> ::= <V> <VList> | null ; 8 <RightPartList> ::= "|" <Canditate> <RightPartList> | null ; 9 <V> ::= <Vn> | <Vt> ; 10 <Vn> ::= "<" identifier ">" ; 11 <Vt> ::= "null" | "identifier" | "number" | "constString" | constString ; 12 ==================================================================== 13 143 set action items 14 <Grammar> ::= <Production> <ProductionList> ; 15 <ProductionList> ::= <Production> <ProductionList> | null ; 16 <Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ; 17 <Canditate> ::= <V> <VList> ; 18 <VList> ::= <V> <VList> | null ; 19 <RightPartList> ::= "|" <Canditate> <RightPartList> | null ; 20 <V> ::= <Vn> | <Vt> ; 21 <Vn> ::= "<" identifier ">" ; 22 <Vt> ::= "null" | "identifier" | "number" | "constString" | constString ; 23 ==================================================================== 24 139 set action items 25 <Grammar> ::= <ProductionList> <Production> ; 26 <ProductionList> ::= <ProductionList> <Production> | null ; 27 <Production> ::= <Vn> "::=" <LeftPartList> <Canditate> ";" ; 28 <LeftPartList> ::= <LeftPartList> <LeftPart> | null ; 29 <LeftPart> ::= <Canditate> "|" ; 30 <Canditate> ::= <V> <VList> ; 31 <VList> ::= <V> <VList> | null ; 32 <V> ::= <Vn> | <Vt> ; 33 <Vn> ::= "<" identifier ">" ; 34 <Vt> ::= "null" | "identifier" | "number" | "constString" | constString ; 35 ==================================================================== 36 120 set action items 37 <Grammar> ::= <ProductionList> <Production> ; 38 <ProductionList> ::= <ProductionList> <Production> | null ; 39 <Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ; 40 <Canditate> ::= <VList> <V> ; 41 <VList> ::= <VList> <V> | null ; 42 <RightPartList> ::= "|" <Canditate> <RightPartList> | null ; 43 <V> ::= <Vn> | <Vt> ; 44 <Vn> ::= "<" identifier ">" ; 45 <Vt> ::= "null" | "identifier" | "number" | "constString" | constString ;
ContextfreeGrammars
总结
实现了LALR(1)分析和GLSL解析器。
今后做任何语言、格式的解析都不用愁了。